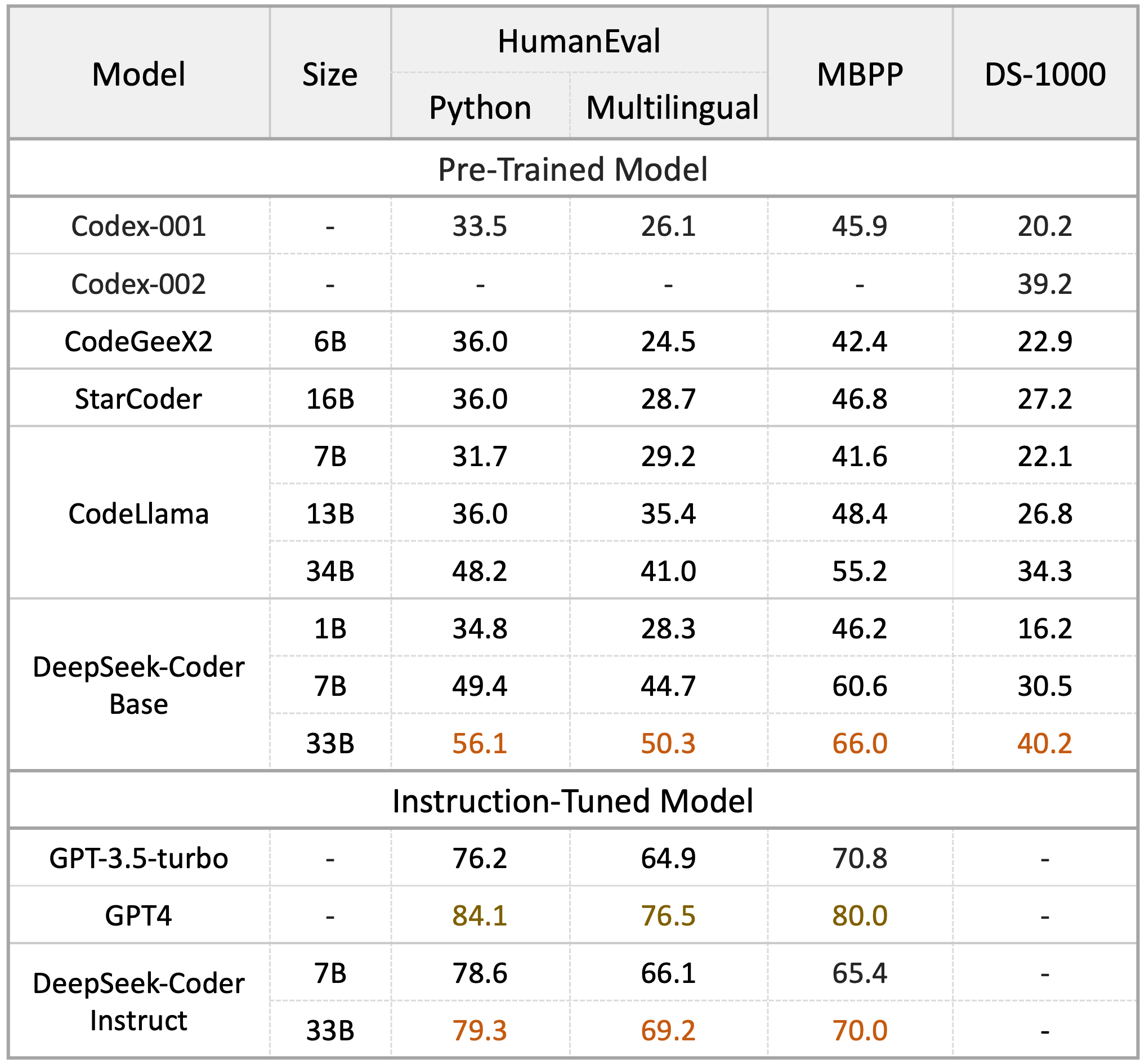
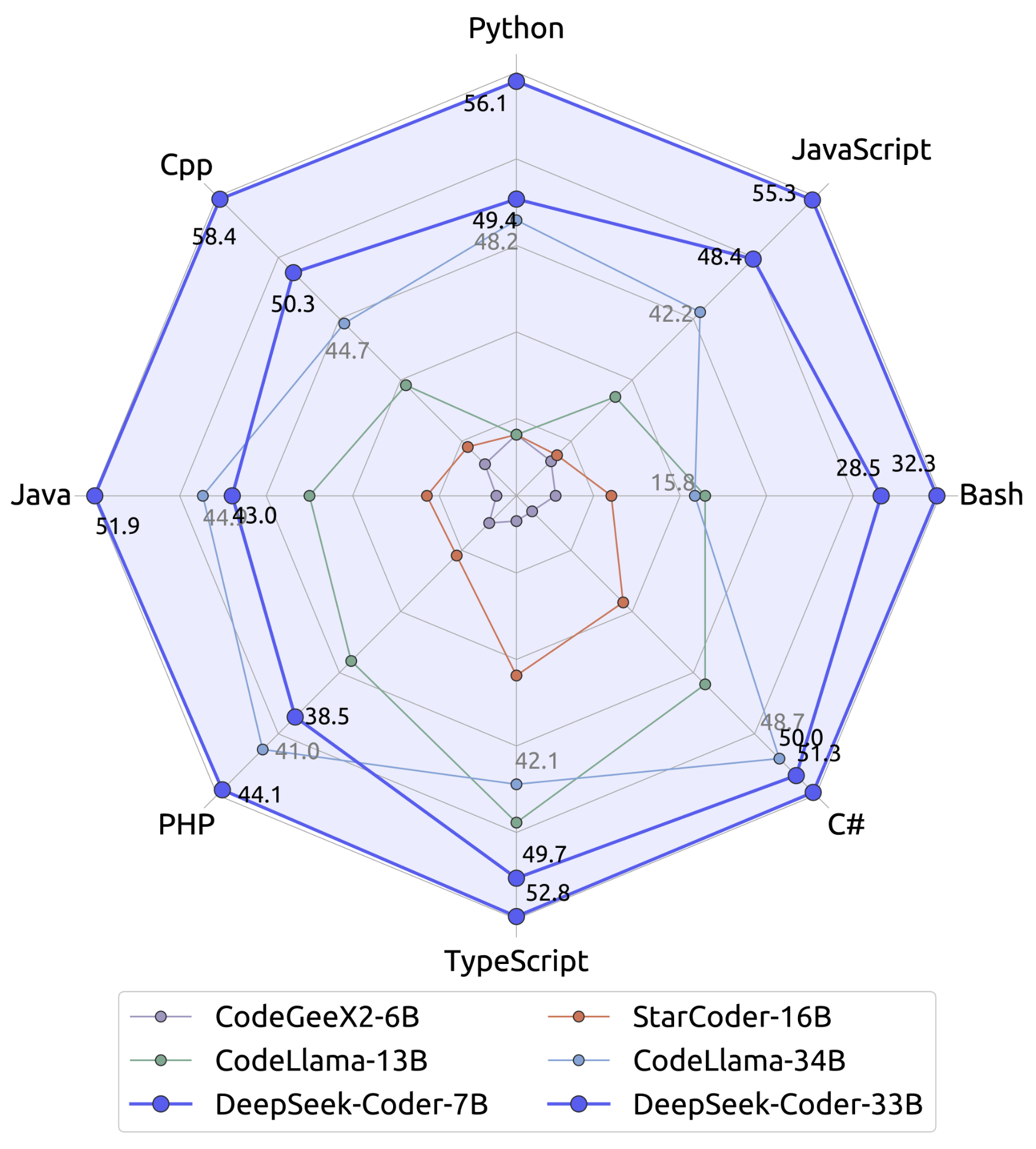
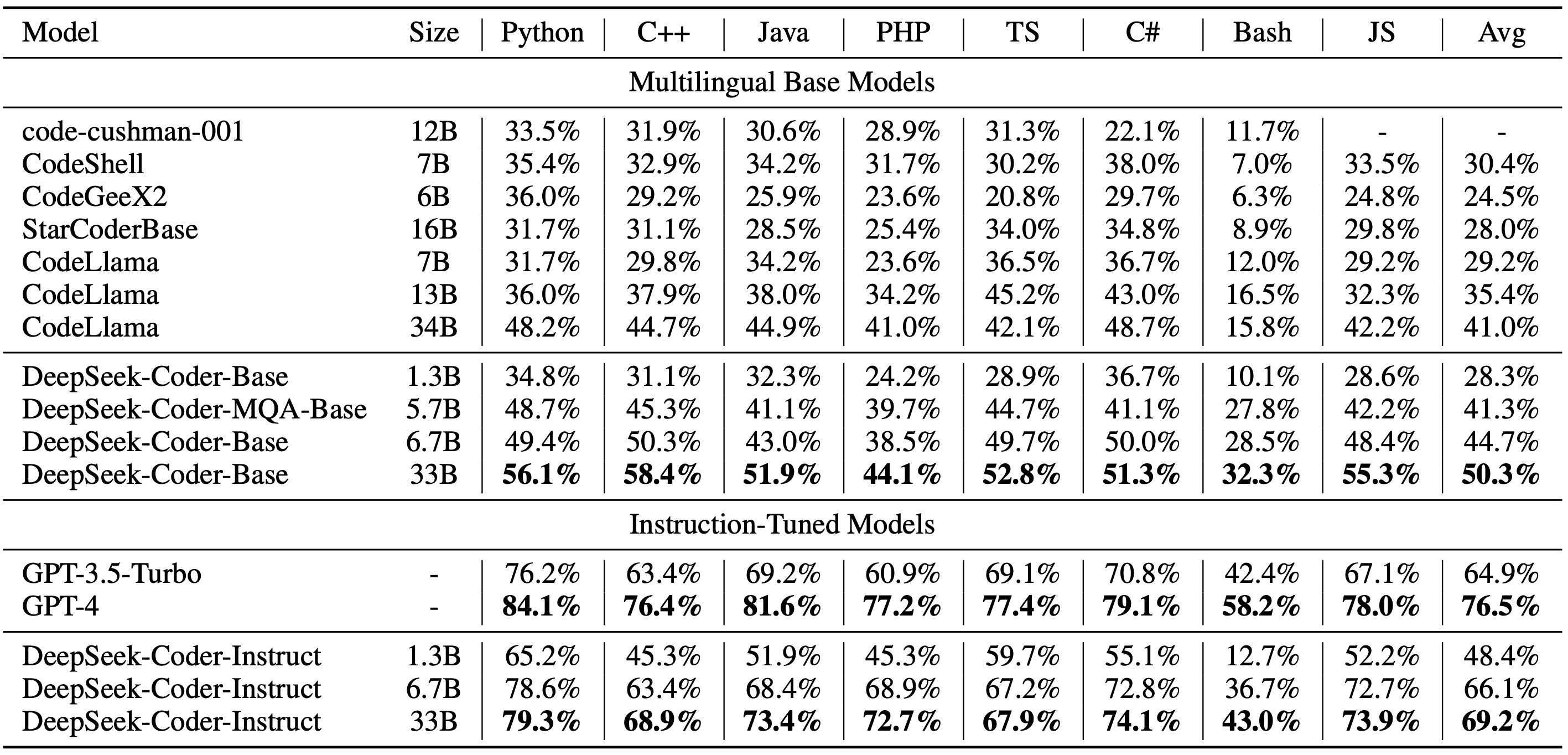
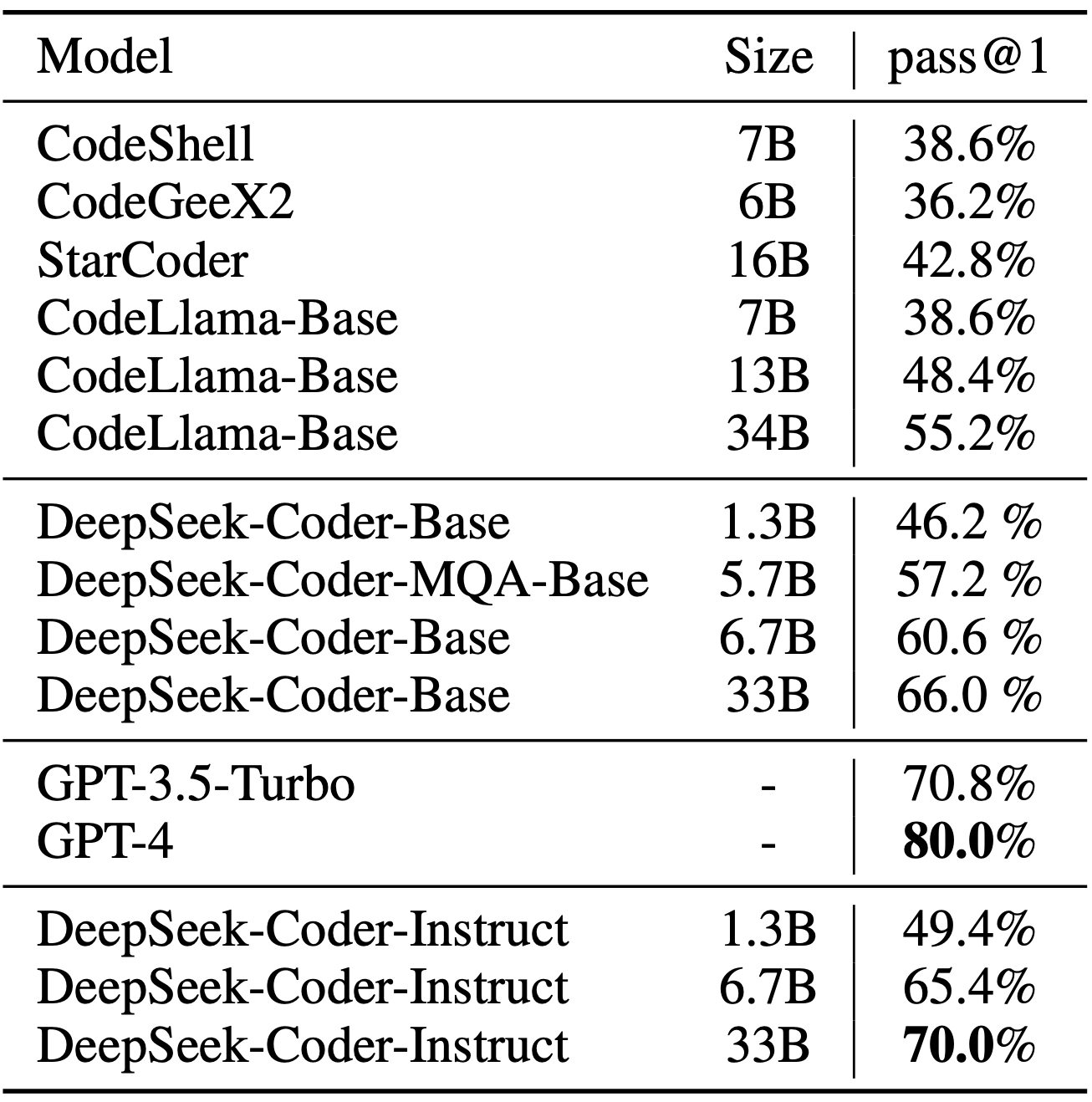
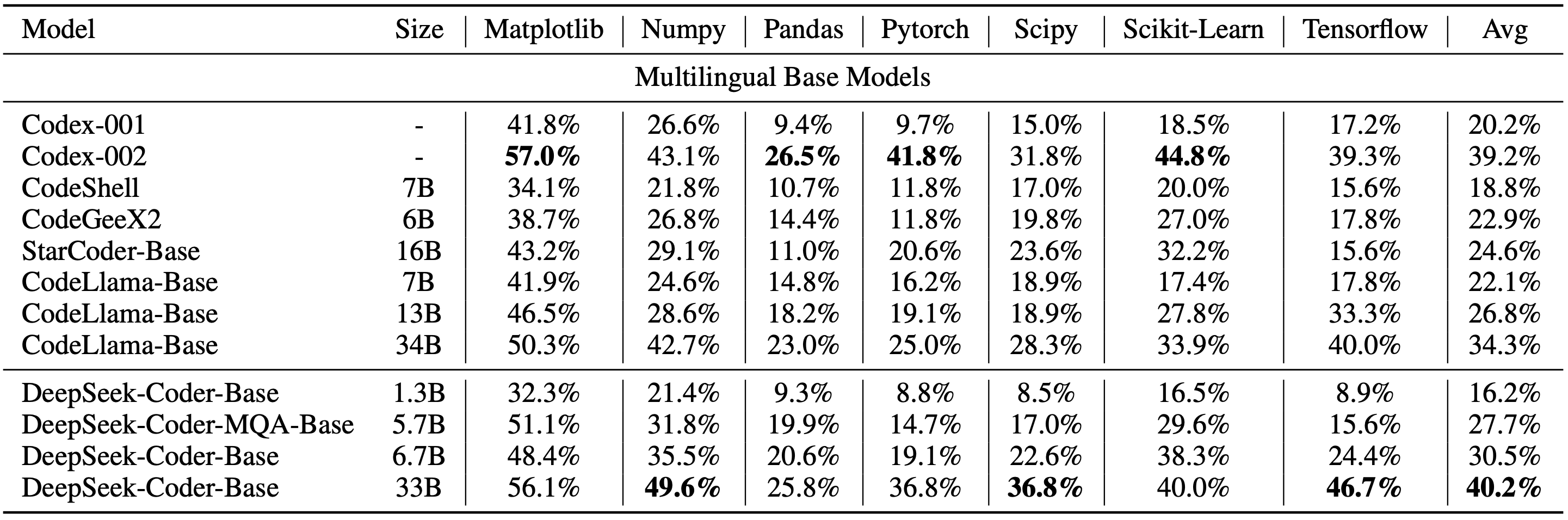
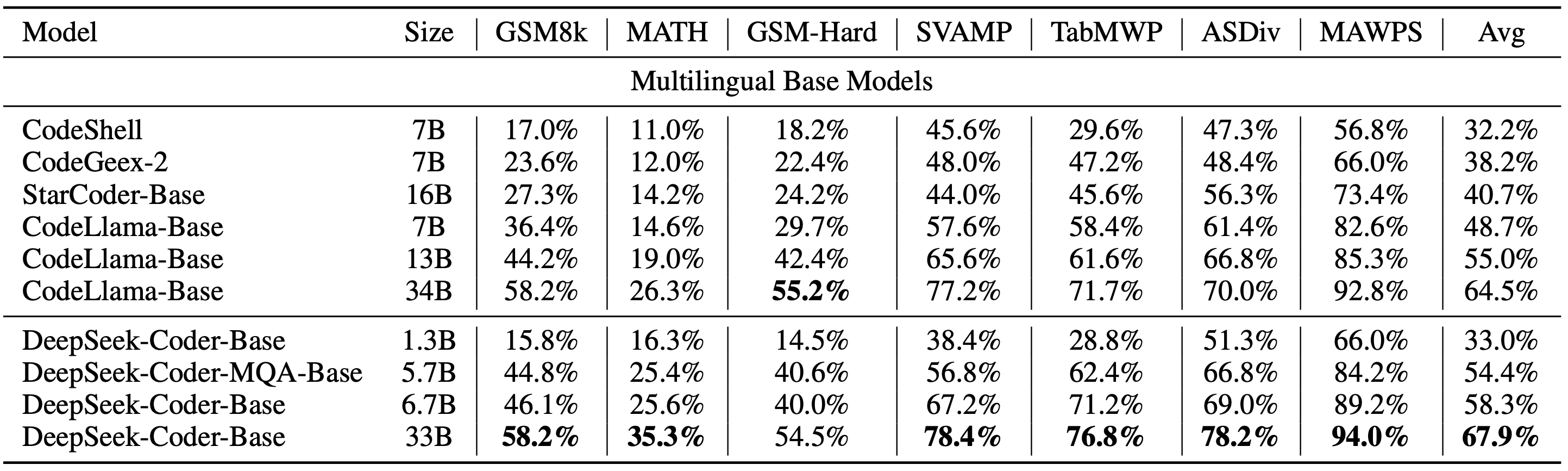
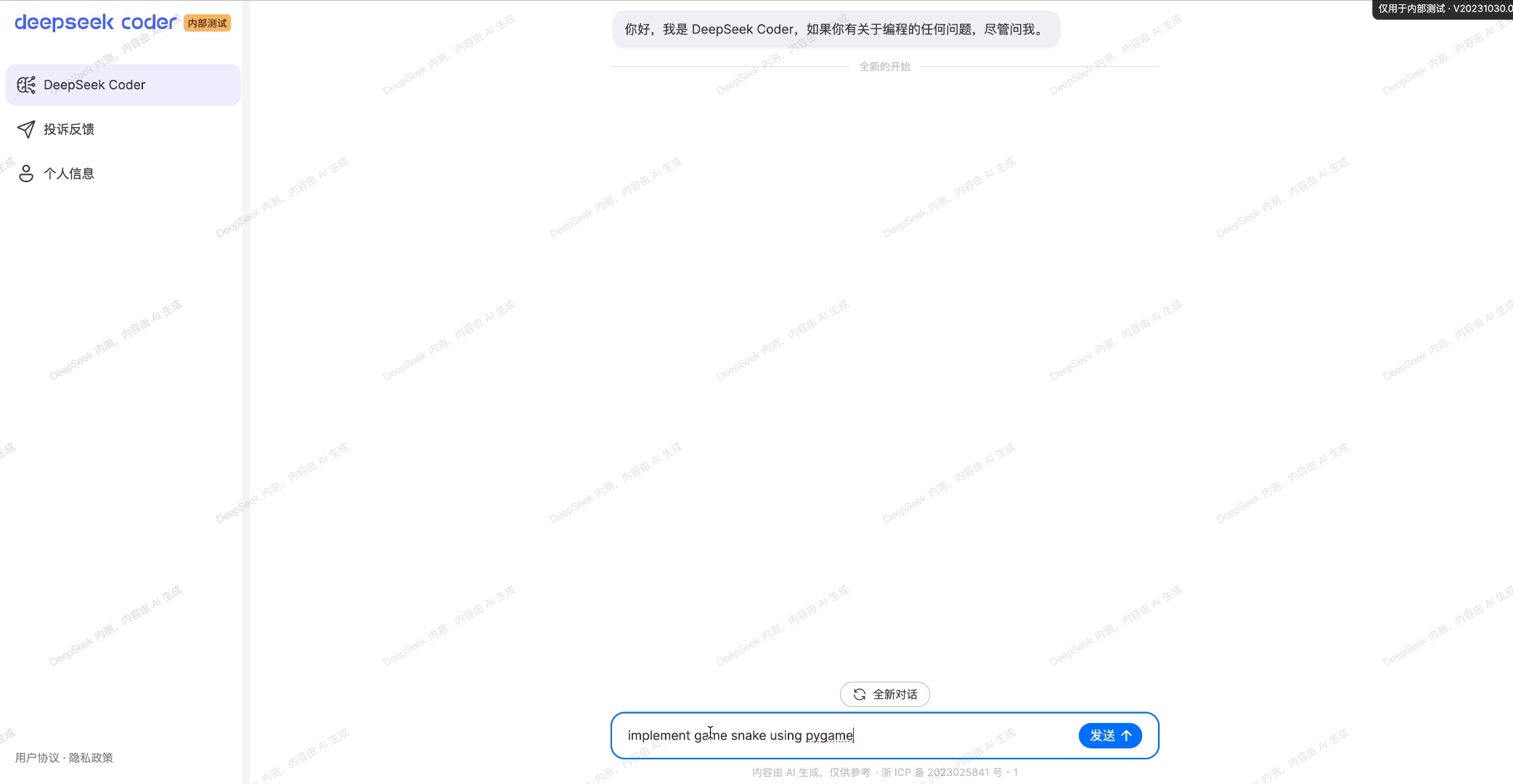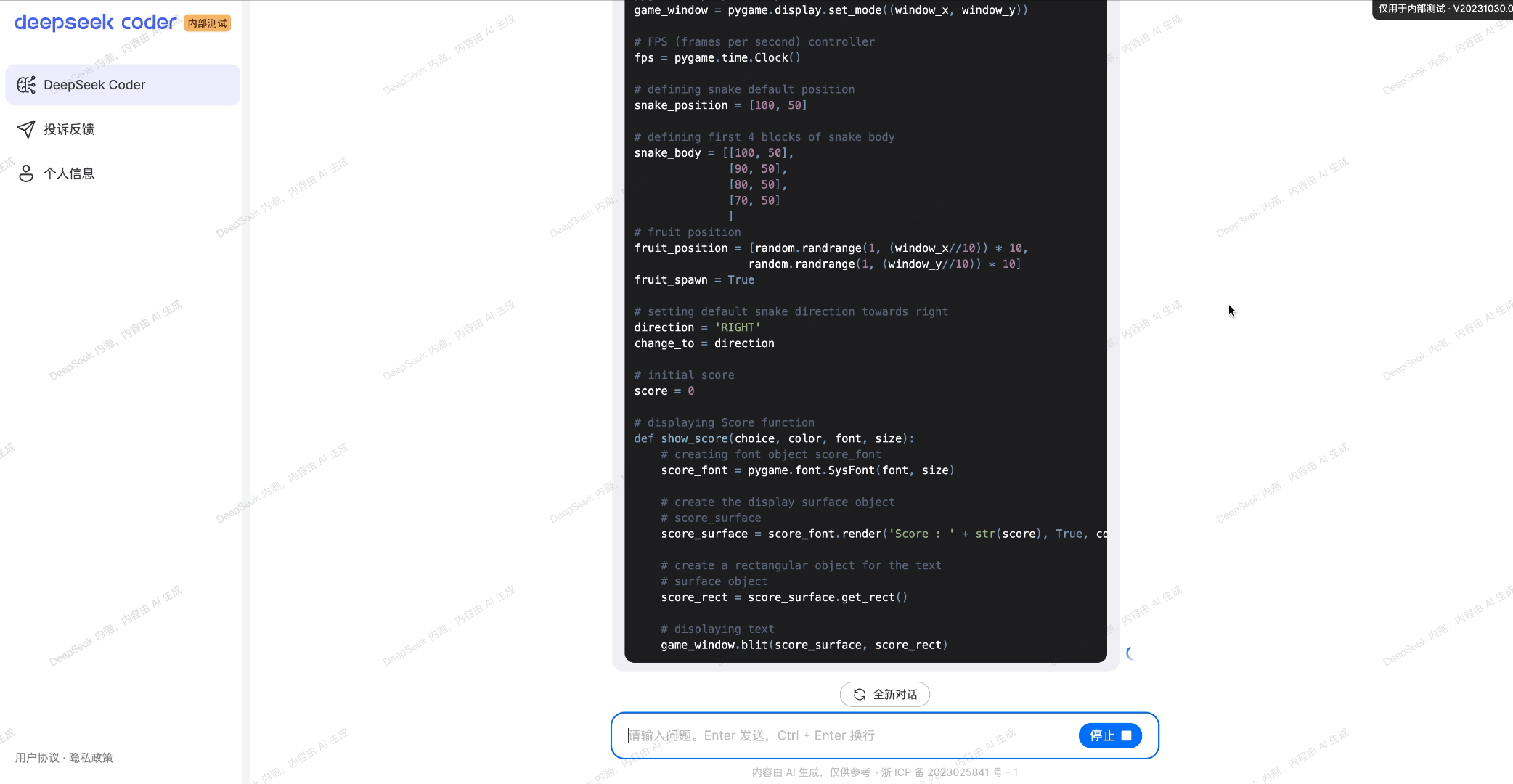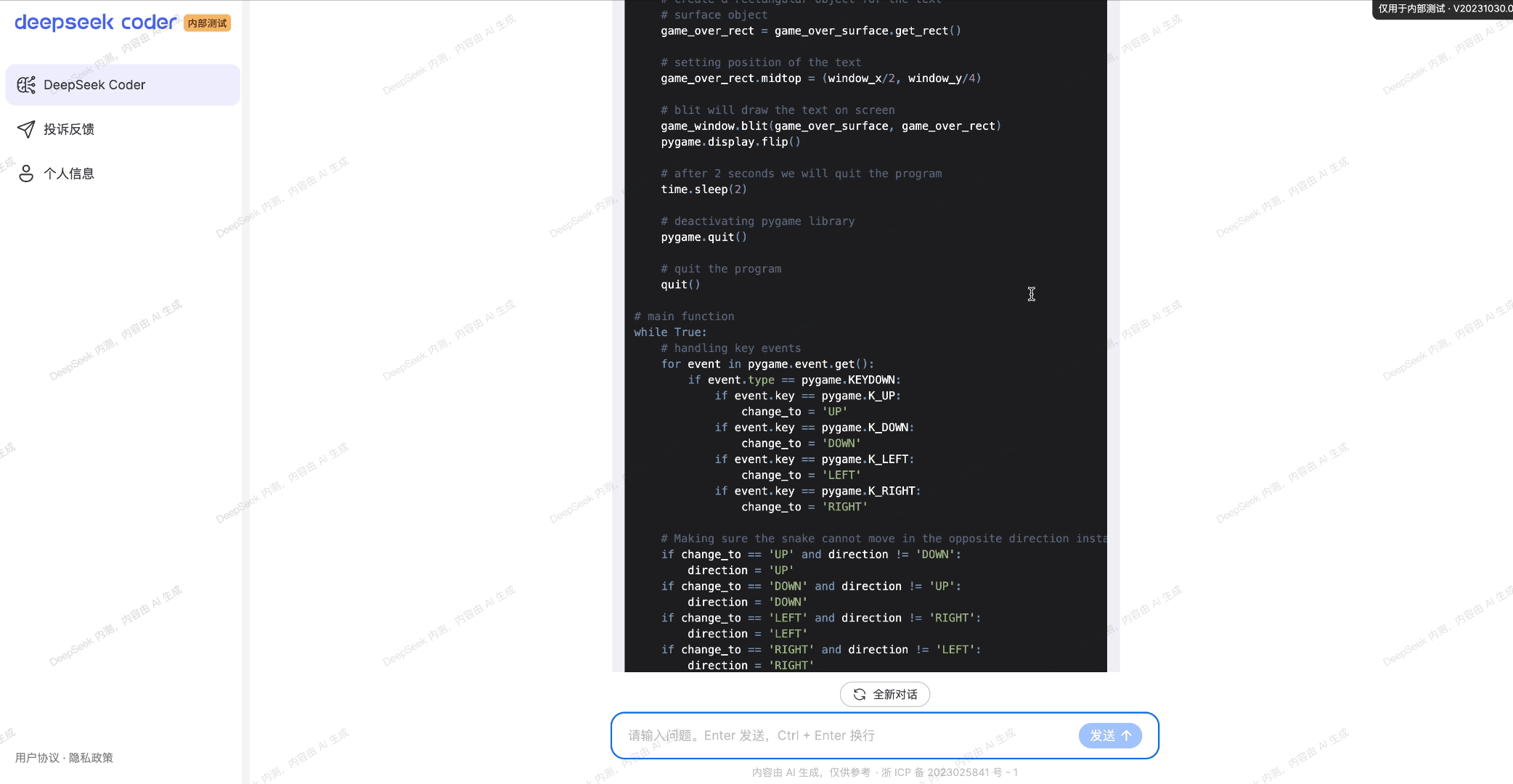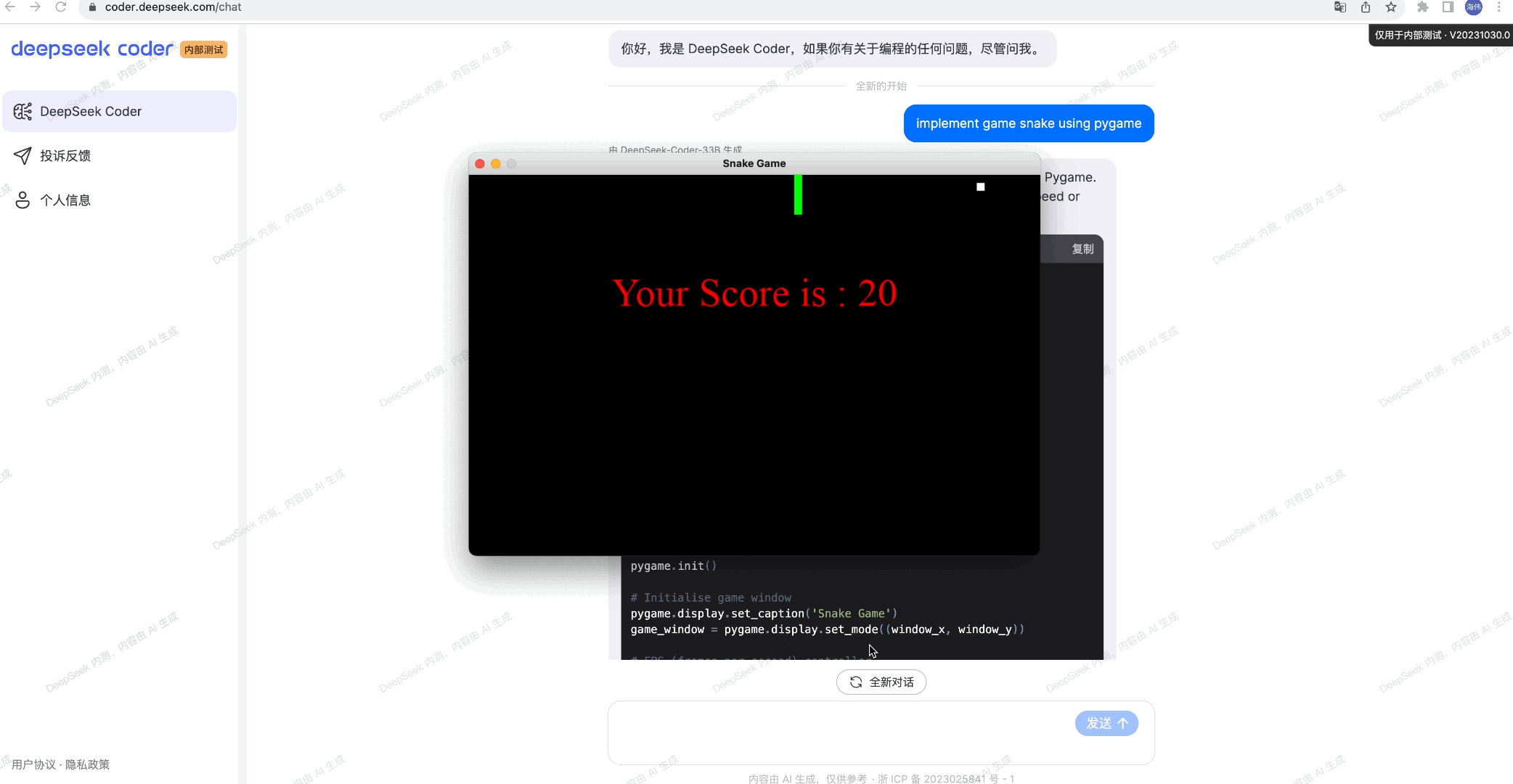
We evaluate DeepSeek Coder on various coding-related benchmarks. The result shows that DeepSeek-Coder-Base-33B significantly outperforms existing open-source code LLMs. Compared with CodeLLama-34B, it leads by 7.9%, 9.3%, 10.8% and 5.9% respectively on HumanEval Python, HumanEval Multilingual, MBPP and DS-1000. Surprisingly, our DeepSeek-Coder-Base-7B reaches the performance of CodeLlama-34B. And the DeepSeek-Coder-Instruct-33B model after instruction tuning outperforms GPT-3.5-turbo on HumanEval and achieves comparable result with GPT-3.5-turbo on MBPP.
 DeepSeek-Coder].
DeepSeek-Coder].If you have any questions, please raise an issue or contact us at agi_code@deepseek.com.
{kind=link}